Visual semantics definition
When you try to describe the content of an image, what type of words do you use? Do those words focus on the high-level event that occured, on objects within the image, the background scene in the image, or perhaps the location depicted? While the goal of visual semantics is to allow computers to describe images with similar ease, they are instead reliant on pixels that represent low-level colors, edges, and texture patterns. This problem is often referred to as the "semantic gap" between human and computer descriptions of content.
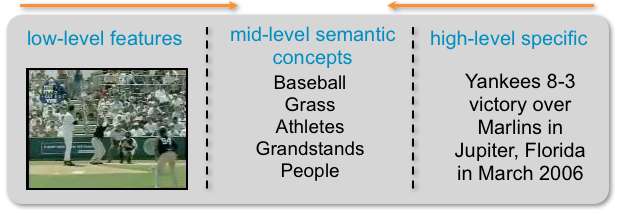
Visual semantics, also called semantic concepts, create a mid-level definition of concepts that both humans and computers can use to describe visual content. The image above illustrates an example scenario where the same sporting event can be described in a number of ways. Utilizing a trained set of visual classifiers, visual semantics facilitate the automatic description of content by computer-generated metadata that enables alternative indexing and .
Defining a Semantic Lexicon
The lexicon, or dictionary, of available visual classifiers is a critical part of an effective visual semantic system. Although visual semantics have been discussed in literature for several years, until recently a large-scale definition and public release of annotation data was unavailable. The LSCOM effort, supported by the data of TRECVID, an evaluation event sponsored by NIST annotated over four hundred visual semantics on a database of over 61 thousand images with expectations to extend that definition to another 600 visual semantics.
Fast Content Search with Concept Filtering
While some efforts have focused on fast retrieval with speech and image objects, visual semantics also provide a unique way to quickly traverse a large database of video content. In prior work, six months of television programs were analyzed and indexed with a set of visual semantics. Afterwards, using statistically determined thresholds, each visual semantic was binarized (i.e. the semantic is either present or absent) for every image in the database.
With a binary representation of visual semantics, it is trivial to then use visual semantics in simple logical formulations. For example, to find "a car accident in the snow", a user could use the semantic car and require additional semantics snow and emergency. In the example animations below, visual semantics are combined with local AND and OR operations to continually improve the quality of retrieved images starting from the semantic query "basketball".
You might also like




|
Tosbuy Mesh Slip on Water Shoes for Women(eu37,gray) Shoes
|