- Meetup")
Web. Semantic technologies
At Alfresco DevCon 2012 in Berlin I presented Alfresco & the Semantic Web.The focus of the presentation is how semantic technologies can be used to enable the discovery of information within an Alfresco repository and improve the user experience.
The agenda of the presentation;
- Introduction to Semantic Web and Semantic Technologies: Introduction described the Semantic Web and Linked Data. I also explained the difference between these two concepts, and the importance of describing the data.
- IKS Project: Zaizi were one of the early adopters of IKS, within Alfresco. I also explained the different IKS projects: IKS, Apache Stanbol and VIE.
- ECKM - Enterprise Content and Knowledge Management: The internal project name at Zaizi for the integration of ECM and Semantic Web/Technologies. The functionalities presented were: language detection, entity extraction, semantic annotations and intelligent search.
I got great feedbacks for this presentation. Below, I documented all the functionalities I demonstrated so you can also enjoy the "Alfresco & the Semantic Web" demo. I'll write another separate post explaining Semantic Web/Technologies or IKS technologies.
Language detection
International companies with offices worldwide, create documents in multiple languages. With the language detection functionality, they can auto-detect the language in which documents are written so it can be indexed correctly by the search engine. Apache Solr search engine can use this to index content correctly and to build facets by language. This enables us to provide pretty much the same functionality that Google does: Pages in English. Some documents even have more than one language (e.g. a contract in two languages).
Entity extraction
The metadata for a document or content is only just a small percentage of useful information within that document. A lot of information is held within the unstructured body of the document. With the entity extraction functionality, we can identify useful data within the content and annotate with additional metadata. Entities can be names of people, places or organisations mentioned within the body of the document. Using this extracted information we can help users navigate and discover documents in new ways through richer user interfaces. With these entities we can create relationships among documents.
You might also like





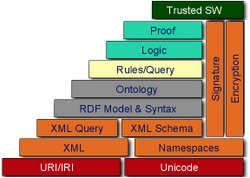 The Semantic Web is a collaborative movement led by the World Wide Web Consortium (W3C) that promotes common formats for data on the World Wide Web. By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web of unstructured documents into a "web of data". It builds on the W3C's Resource...
The Semantic Web is a collaborative movement led by the World Wide Web Consortium (W3C) that promotes common formats for data on the World Wide Web. By encouraging the inclusion of semantic content in web pages, the Semantic Web aims at converting the current web of unstructured documents into a "web of data". It builds on the W3C's Resource...